I’ve recently been binge-reading The Guardian Experience columns. I’m a big fan of The Guardian life and style section regulars: the blind dates to which I dedicated a blog post, Oliver Burkeman’s This column will change your life, etc. Experience is another regular that I enjoy a lot. In each of the column, someone tells something remarkable that happened to them. It can really be anything.
I was thinking of maybe scraping the titles and get a sense of most common topics. The final push was my husband’s telling me about this article of Gabriella Paiella’s about the best Guardian Experience columns. She wrote “the “Experience” column does often touch on heavier topics”. Can one know what is the most prevalent “weight” of Experience columns scraping all their titles?
Experience: I downloaded all the titles of The Guardian Experience columns
I learnt a lot about responsible (and elegant) webscraping from Bob Rudis, and decided to use the tool he mentioned in this blog post, the robotstxt package which “makes it easy to check if bots (spiders, crawler, scrapers, …) are allowed to access specific resources on a domain.”
robotstxt::get_robotstxt("https://www.theguardian.com")
## # this is the robots.txt file for theguardian.com
##
## User-agent: *
## Disallow: /sendarticle/
## Disallow: /Users/
## Disallow: /users/
## Disallow: /*/print$
## Disallow: /email/
## Disallow: /contactus/
## Disallow: /share/
## Disallow: /websearch
## Disallow: /*?commentpage=
## Disallow: /whsmiths/
## Disallow: /external/overture/
## Disallow: /discussion/report-abuse/*
## Disallow: /discussion/report-abuse-ajax/*
## Disallow: /discussion/comment-permalink/*
## Disallow: /discussion/report-abuse/*
## Disallow: /discussion/user-report-abuse/*
## Disallow: /discussion/handlers/*
## Disallow: /discussion/your-profile
## Disallow: /discussion/your-comments
## Disallow: /discussion/edit-profile
## Disallow: /discussion/search/comments
## Disallow: /discussion/*
## Disallow: /search
## Disallow: /music/artist/*
## Disallow: /music/album/*
## Disallow: /books/data/*
## Disallow: /settings/
## Disallow: /embed/
## Disallow: /*styles/js-on.css$
## Disallow: /sport/olympics/2008/events/*
## Disallow: /sport/olympics/2008/medals/*
## Disallow: /f/healthcheck
## Disallow: /sections
## Disallow: /top-stories
## Disallow: /most-read/sport
## Disallow: /articles
## Disallow: /podcasts
## Disallow: /global$
## Disallow: /*/feedarticle/*
## Disallow: /travel/2013/aug/22/been-there-readers-competition?*
## Disallow: /preference/*
## Disallow: /59666047/
## Disallow: /print/
## Disallow: /info/tech-feedback
## Disallow: /production-monitoring/
##
## User-agent: Mediapartners-Google
## Disallow:
##
## Sitemap: http://www.theguardian.com/sitemaps/news.xml
## Sitemap: http://www.theguardian.com/sitemaps/video.xml
##
## User-agent: bingbot
## Crawl-delay: 1
robotstxt::paths_allowed("https://www.theguardian.com/lifeandstyle/series/experience")
## [1] TRUE
If I understand the above correctly, I’m allowed to scrape the titles of the columns, great!
I also noticed the crawl delay at the end of the robots.txt, of 1 second. Since I’ve decided to be a really nice scraper and also because I only have 29 pages to scrape in total, I’ll use a delay of 2 seconds between requests. In his post Bob says that if there is no indication, you should wait 5 seconds.
After these checks, I started working on the scraping itself.
library("rvest")
xtract_titles <- function(node) {
css <- 'span[class="js-headline-text"]'
html_nodes(node, css) %>% html_text(trim = TRUE)
}
get_titles_from_page <- function(page_number){
Sys.sleep(2)
link <- paste0("https://www.theguardian.com/lifeandstyle/series/experience?page=", page_number)
page_content <- read_html(link)
xtract_titles(page_content)
}
experience_titles <- purrr::map(1:29, get_titles_from_page) %>% unlist()
save(experience_titles, file = "data/2017-10-02-guardian-experience.RData")
set.seed(1)
sample(experience_titles, 10)
## [1] "Experience: pregnancy sickness nearly killed me"
## [2] "Experience: I was a sperm donor for my friends"
## [3] "Experience: I was attacked in my front garden"
## [4] "I was brought up in the exclusive brethren"
## [5] "Experience: I am Dancing Man"
## [6] "The boy who missed the mainstream"
## [7] "I still can't explain what I saw"
## [8] "Experience: My twin rewrote my childhood"
## [9] "Experience: I've renewed my wedding vows more than 50 times"
## [10] "Experience: I talk with my eyes"
See, these are really diverse topics! And I think this sample of 10 titles actually shows many heavy topics.
Experience: I computed the most frequent words
I’ll first remove the “Experience: " part of many titles, since it’s not exactly the most interesting word.
experience_titles <- stringr::str_replace(experience_titles, "^Experience: ", "")
I then unnested words. Interestingly in order to remember how to do this I went and read my Guardian blind dates post (the “So what did they talk about?” part).
library("tidytext")
library("rcorpora")
stopwords <- corpora("words/stopwords/en")$stopWords
words <- tibble::tibble(title = experience_titles) %>%
unnest_tokens(word, title) %>%
dplyr::filter(!word %in% stopwords) %>%
dplyr::count(word, sort = TRUE)
knitr::kable(words[1:20,])
| word | n |
|---|---|
| years | 23 |
| fell | 21 |
| lost | 20 |
| saved | 20 |
| life | 19 |
| man | 19 |
| baby | 15 |
| killed | 13 |
| survived | 13 |
| car | 12 |
| daughter | 12 |
| love | 12 |
| father | 11 |
| friend | 11 |
| husband | 11 |
| birth | 9 |
| dad | 8 |
| married | 8 |
| attacked | 7 |
| days | 7 |
In my opinion this list of the most common words support my feeling topics are often heavy, but I also think it might be because there are many, many different words that can describe a light topic while well death will be primarily described by “killed”. Could sentiment analysis of the titles help me?
Experience: I computed the sentiment of titles
afinn <- get_sentiments("afinn")
sentiment <- tibble::tibble(title = experience_titles) %>%
dplyr::mutate(saved_title = title) %>%
unnest_tokens(word, title) %>%
dplyr::inner_join(afinn) %>%
dplyr::group_by(saved_title) %>%
dplyr::summarize(sentiment = sum(score)) %>%
dplyr::filter(!is.na(sentiment))
knitr::kable(sentiment[1:10,])
| saved_title | sentiment |
|---|---|
| ‘I stopped a terrorist attack’ | -2 |
| a coup interrupted our wedding | -2 |
| A great white shark ate my leg | 3 |
| a head injury made me a musical prodigy | -2 |
| a ladybird nearly killed me | -3 |
| A machine keeps me alive | 1 |
| A six-metre wall collapsed on top of me | 0 |
| Becoming homeless helped me find love | 3 |
| Being obese made me feel like a social outcast | 2 |
| Blind date | -1 |
library("ggplot2")
library("hrbrthemes")
ggplot(sentiment) +
geom_bar(aes(sentiment)) +
theme_ipsum_rc()
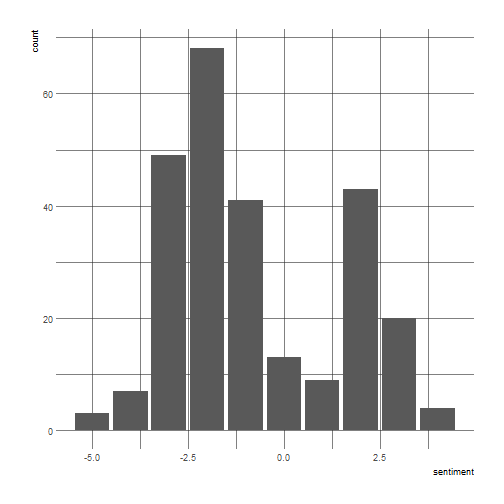
Honestly, I think sentiment analysis didn’t help much here: the titles are too short, and the sample presented above is not very convincing. Moreoever, would the sentiment reveal the dramatic intensity of light vs. heavy, anyway?
Experience: I tried using machine learning to derive a topic from the title
In the following I’ll use my own monkeylearn package and in particular this topic classifier without too much hope since I’m feeding it a title, not a whole article.
topics <- monkeylearn::monkeylearn_classify(experience_titles,
classifier_id = "cl_5icAVzKR")
titles <- tibble::tibble(title = experience_titles,
text_md5 = purrr::map_chr(experience_titles, digest::digest, algo = "md5"))
titles <- dplyr::inner_join(titles, topics, by = "text_md5")
Here’s a sample of the results after an arbitrary filtering based on probability:
titles <- dplyr::filter(titles, probability > 0.5)
set.seed(1)
dplyr::sample_n(titles, size = 20) %>%
dplyr::select(title, label, probability) %>%
knitr::kable()
| title | label | probability |
|---|---|---|
| my family was attacked by lions | Land Mammals | 0.680 |
| Muhammad Ali was my mentor | Religion & Spirituality | 0.681 |
| I’m a championship arm-wrestler | Entertainment & Recreation | 0.873 |
| I lit my father’s funeral pyre | Relationships | 0.603 |
| I have sudden death syndrome | Health & Medicine | 0.816 |
| One drink and I’m dead | Food & Drink | 0.511 |
| I was a compulsive gambler | Mental health | 0.805 |
| I flew the English Channel using a bunch of balloons | Aircraft | 0.828 |
| I crushed my £1m violin | Humanities | 0.625 |
| I crashed into the North Sea | Travel | 0.549 |
| I said yes to marriage the first time we met | Society | 0.775 |
| I can fly | Aircraft | 0.930 |
| We were told our son has cystic fibrosis – he hasn’t | Special Occasions | 0.511 |
| I found out I’m not my son’s father | Society | 0.521 |
| I became a famous artist at the age of 94 | Music | 0.673 |
| I was impaled while pregnant | Mental health | 0.548 |
| A great white shark ate my leg | Animals | 0.656 |
| The holiday capsule wardrobe | Accommodation | 0.761 |
| I don’t wear shoes | Beauty & Style | 0.798 |
| I became a famous artist at the age of 94 | Art | 0.531 |
Note that after this filtering I had at least one topic for 288 titles. I don’t think this classification is really useful either but at least it’s fun to look at the proposed topic. What are the most frequent ones?
titles %>%
dplyr::group_by(label) %>%
dplyr::summarise(n = n(),
some = toString(title[1:3])) %>%
dplyr::arrange(dplyr::desc(n)) %>%
head(n = 10) %>%
knitr::kable()
| label | n | some |
|---|---|---|
| Transportation | 45 | I pulled a man from a burning car, I was hit by a car doing 101mph, a car crashed into me in the bath |
| Relationships | 36 | I’m a divorce party planner, a coup interrupted our wedding, my husband didn’t meet our daughter until she was 27 |
| Society | 32 | my husband didn’t meet our daughter until she was 27, I first met my mother at a party, I was accused of having a sham marriage |
| Land Vehicles | 30 | I pulled a man from a burning car, I was hit by a car doing 101mph, a car crashed into me in the bath |
| Special Occasions | 29 | I fell in love through Airbnb, I made peace with my daughter’s killer, I’ve been protesting for more than 60 years |
| Animals | 26 | my dog rescues cats, I accidentally bought a giant pig, I was bitten by a shark |
| Parenting | 19 | I had a free birth, I saved a stranger’s life, We found a baby in a manger |
| Travel | 16 | a car crashed into me in the bath, I crashed into the North Sea, I saved my school bus from crashing |
| Land Mammals | 15 | my dog rescues cats, my cat saved me from a fire, I own the world’s ugliest dog |
| Health & Medicine | 13 | I have sudden death syndrome, I am afraid of pregnancy, my anti-malaria drugs made me psychotic |
That, in a way, makes me more okay with the classification. I’ve always had the impression (you have to believe me) that many of the columns dealt with accidents, which corresponds to the transportation category, and families and relationships, and well animals, the ones that try to eat you or that steal your tractor. But now does it help me judge whether the Experience columns deal with rather light or heavy topics? Hum, no.
Experience: I could not really answer my initial question
So, it was fun, but I can’t really tell Gabriella Paiella whether she was right or wrong. One thing is sure, these columns are quite varied… so everyone can find what they’re looking for, either a dramatic story or a funny one?