On my pretty and up-to-date CV, one of the first things one sees is my Github username, linking to my Github profile. What does a potential employer look at there? Hopefully not my non informative commit messages… My imitating a red Ampelmann, my being part of several organizations, my pinned repositories described with emojis… But how would they know where&how I’ve mostly been active without too much effort?
A considerable part of my Github work happens in organizations: I’m a co-editor at rOpenSci onboarding of packages, I contribute content to the R Weekly newsletter, etc. Although my profile shows the organizations I belong to, one would need to dig into them for a while before seeing how much or how little I’ve done. Which is fine most of the time but less so when trying to profile myself for jobs, right? Let’s try and fetch some Github data to create a custom profile.
Note: yep I’m looking for a job and ResearchGate’s suggestions are not helpful! Do you need an enthusiastic remote data scientist or research software engineer for your team? I’m available up to 24 hours a week! I care a lot about science, health, open source and community. Ideally I’d like to keep working in something close to public research but we can talk!
Getting all my activity
Note: for another look at Github activity, more related to when people work, check out Dean Attali’s cool Shiny app!
I’m a big fan of the simplistic gh package that I’ve used in my blog post about initial/first commits and in my blog post about random seeds. My workflow is reading the API documentation to find which endpoints I need to answer my question, then writing code that loops/maps over pages of answers from the API and unnests results, all of this inspired by the package README and now my own old posts. If I used this data more often, I imagine I’d need less copy-pasting from my previous uses, but in this situation I’m very happy that my past self published this stuff. I’m also thankful I set a GITHUB_PAT environment variable as explained here.
The problem with the /users/:username/events/public endpoint of Github API is that it only provides you with the 300 latest events from an user, which is not enough, so I had to branch out and look at another source of data, Github archive via Google BigQuery. I had never touched it and will let Google’s own words define it: “BigQuery is Google’s fully managed, petabyte scale, low cost analytics data warehouse.”. To interact with this tool, there are at least two R packages, bigQueryR and bigrquery. I chose the latter after reading the short comparison from the website of the former. I created a project as explained here.
After that, here is the code I ran. I mostly adapted the example from Github archive page to:
-
ask for all my events in the last two years but not at once because of my quota for query bytes;
-
ask for my events either with my current username “maelle” or the one I had before that, “masalmon” (by the way I’m so happy I could claim “maelle” because that user was not active! I love having people use my first name to ping me!);
-
get all the events, not only issues opened, and their creation date.
It took me less time as expected to get it, I was helped by my familiarity with Github data and with SQL queries, or my capacity to update existing queries to serve my needs, ahahah.
I started out using the basic free tier, but it turned out I was reaching the quota by query all the time, so it was not going to work. I tried changing my query but finally took the plunge and used the free trial. You get 300$, and one TB of query costs 5$. One day queried by the code below is equivalent to something in the magnitude of 10 gigabytes processed, so I was going to be fine (see the pricing information).
# using the very handy anytime package!
dates <- seq(from = anytime::anydate("2015-12-20"),
to = anytime::anydate("2017-12-19"),
by = "1 day")
library("bigrquery")
get_one_day_events <- function(day){
project <- #projectid here
sql <- paste0("/* count of issues opened, closed, and reopened between 1/1/2015 and 2/1/2015 */
SELECT type, repo.name, actor.login, created_at,
JSON_EXTRACT(payload, '$.action') as event,
FROM (TABLE_DATE_RANGE([githubarchive:day.],
TIMESTAMP('",
as.character(day),
"'),
TIMESTAMP('",
as.character(day + 1), "')
))
WHERE (actor.login = 'maelle' OR actor.login = 'masalmon')
;")
results <- try(query_exec(sql, project = project), silent = TRUE)
if(is(results, "try-error")){
return(NULL)
}else{
return(results)
}
}
my_events <- purrr::map_df(dates, get_one_day_events)
readr::write_csv(my_events, path = "data/2017-12-20-my_events.csv")
I realized after the fact that I had done overlapping queries, well they overlapped in time so I got many events twice… Stupid me.
Now we just need to wrangle the data a little bit. In particular, we’ll use the snakecase package to convert the upper camel case of the type column into something prettier (in my opinion).
# no duplicate
my_events <- unique(my_events)
# Better format for the type
my_events <- dplyr::mutate(my_events, type = stringr::str_replace(type, "Event", ""))
my_events <- dplyr::mutate(my_events, type = snakecase::to_parsed_case(type))
my_events <- dplyr::mutate(my_events, type = stringr::str_replace_all(type, "_", " "))
my_events <- dplyr::mutate(my_events, type = tolower(type))
# get repo owner
my_events <- dplyr::mutate(my_events, owner = stringr::str_replace_all(repo_name, "/.*", ""))
# save with a fantastic filename... sigh
readr::write_csv(my_events, path = "data/2017-12-20-my_events_clean.csv")
We got 4991 events from 2015-12-28 09:53:23 to 2017-12-20 06:43:44!
set.seed(42)
knitr::kable(dplyr::sample_n(my_events, size = 10))
| type | repo_name | actor_login | created_at | event | owner |
|---|---|---|---|---|---|
| watch | lindbrook/cholera | maelle | 2017-08-11 15:25:04 | “started” | lindbrook |
| push | maelle/maelle.github.io | maelle | 2017-10-04 17:15:57 | NA | maelle |
| issues | masalmon/monkeylearn | masalmon | 2016-05-19 08:34:51 | “closed” | masalmon |
| issue comment | ropensci/onboarding | maelle | 2017-06-19 06:57:32 | “created” | ropensci |
| issue comment | osmdatar/osmdata | masalmon | 2017-02-15 09:09:59 | “created” | osmdatar |
| issues | ropensci/pdftools | masalmon | 2016-11-23 14:59:16 | “opened” | ropensci |
| issue comment | lockedata/PackageReviewR | maelle | 2017-04-20 12:08:29 | “created” | lockedata |
| issue comment | leeper/colourlovers | masalmon | 2016-03-21 16:30:39 | “created” | leeper |
| issue comment | osmdatar/osmdata | masalmon | 2017-02-27 10:42:37 | “created” | osmdatar |
| push | maelle/eml.tools | maelle | 2017-03-23 11:07:45 | NA | maelle |
Analysing my activity
What kind of events are there?
Events as defined in this Github data can be for instance
-
commenting in issues (main job as an rOpenSci editor, ahah),
-
pushing stuff (sadly this count as one event no matter the size of the commit, which is a limitation of this dataset, and I’m not willing to complete it).
my_events %>%
dplyr::group_by(type) %>%
dplyr::summarize(n = n()) %>%
dplyr::arrange(- n) %>%
knitr::kable()
| type | n |
|---|---|
| push | 1872 |
| issue comment | 1491 |
| issues | 705 |
| watch | 544 |
| create | 151 |
| pull request | 99 |
| fork | 47 |
| commit comment | 34 |
| release | 17 |
| member | 10 |
| pull request review comment | 9 |
| public | 7 |
| delete | 3 |
| gollum | 2 |
All event types are defined here. I had no idea what a Gollum event was, but it’s not surprising given I almost never updated or created a Wiki. Member events are the ones corresponding to that highly exciting moment when you’re added (or well, removed, less exciting) as a collaborator to a repository, or when your permissions are changed.
Regarding the difference between issues events and issue comments event, according to the API docs,
-
an issue event is “Triggered when an issue is assigned, unassigned, labeled, unlabeled, opened, edited, milestoned, demilestoned, closed, or reopened."(at rOpenSci onboarding, we use assignments and labelling a lot)
-
while an issue comment event is “Triggered when an issue comment is created, edited, or deleted.”.
How many events over time?
Although that’s clearly not my goal here, I was curious to have a look at time series of counts of events! You can’t blame me, time series of counts were the subject of my dissertation, in which I luckily did a bit more than plotting some.
We shall concentrate on most frequent events.
library("ggplot2")
library("hrbrthemes")
library("lubridate")
my_events %>%
dplyr::filter(type %in% c("push", "issue comment",
"issues", "watch",
"create", "pull request")) %>%
dplyr::mutate(day = as.Date(created_at),
week = update(day, wday = 1)) %>%
dplyr::group_by(week, type) %>%
dplyr::summarise(n = n()) %>%
ggplot() +
geom_line(aes(week, n)) +
facet_grid(type ~ ., scales = "free_y") +
theme_ipsum(base_size = 20,
axis_title_size = 12) +
theme(legend.position = "none",
strip.text.y = element_text(angle = 0)) +
ggtitle("My Github contributions in the two last years",
subtitle = "Data queried from Github archive on Google BigQuery")
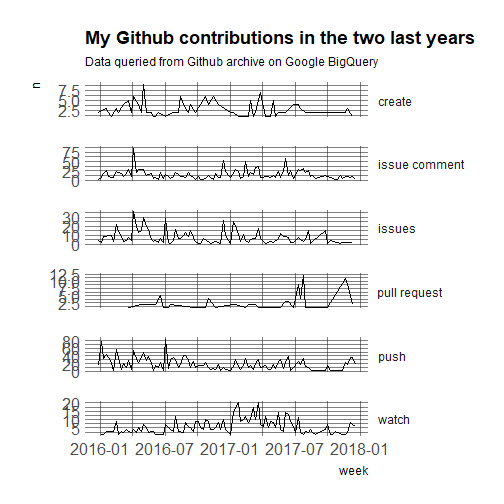
What I notice is:
-
there’s a decrease in my activity, as seen by issue comments and issues created or closed, since the autumn. In September, we moved and had no internet connection for a while, and then we had a baby, with whom I’m now on maternity leave, so this is not a surprise!
-
the number of pushes seems constant which might be surprising given I do code less in my experience… but my pushes, and of pull requests by the way, contain many contributions to R Weekly, where I might update the draft each time I see something interesting to be shared! Now that I’m a member of the organization, I do not need pull requests for that so the number of pull requests is going down, which might be the reason why they added me to the organization… no need to merge my contributions anymore!
-
Speaking of pull requests, this was something I was intimated by (and I haven’t used branches a lot in my own projects) until Jim Hester helped me create my first PR.
-
What Github calls watch events are most often starring events in my case.
A look at the places where I’ve been active
Let’s look where most of my events took place.
my_events %>%
dplyr::group_by(owner) %>%
dplyr::summarize(n = n()) %>%
dplyr::arrange(- n) %>%
dplyr::filter(n > 40) %>%
knitr::kable()
| owner | n |
|---|---|
| masalmon | 1663 |
| ropensci | 974 |
| maelle | 421 |
| ropenscilabs | 364 |
| openaq | 135 |
| osmdatar | 135 |
| rweekly | 113 |
| hrbrmstr | 67 |
| openjournals | 46 |
| cvitolo | 44 |
| rladies | 43 |
My events are scattered among 284 owners and 712 repos (I have starred more than 500 repos). I recognize well my two usernames, rOpenSci organizations ropensci and ropenscilabs, R Weekly, etc. I’m surprised I have many events in OpenAQ organization, I thought my contributions were nearly all in the repo of my R package accessing their data! But thinking of it I did participate in conversations in issues. R-Ladies organization is also not one where I felt I had done that much, because my R-Ladies involvement is much more related to the co-founding and organization of the Barcelona chapter, and these days tweeting for R-Ladies Global. I’m also glad to see “hrbrmstr” a.k.a Bob Rudis, in the complete list there were other such owners: people that have fantastic packages and make it a pleasure to open issues, contribute code, etc.
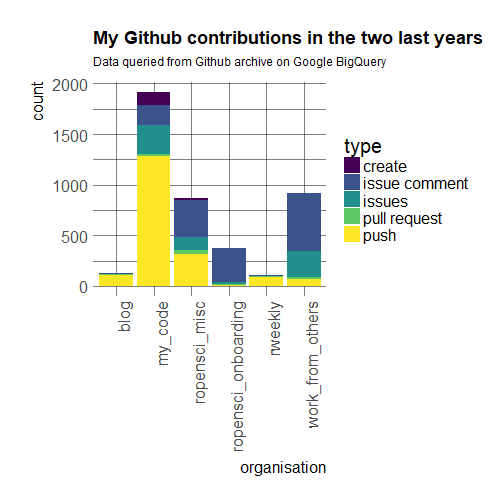
Now I’d like to look at the breakdown of event types by owner of the repo. We’ll change the owner variable a bit to get something more interpretable.
orgs <- dplyr::mutate(my_events,
blog = repo_name == "maelle/maelle.github.io",
my_code = owner %in% c("maelle", "masalmon") & !blog,
ropensci_onboarding = repo_name %in% c("ropensci/onboarding", "ropensci/onboarding-meta"),
ropensci_misc = owner %in% c("ropensci", "ropenscilabs") & !ropensci_onboarding,
rweekly = owner == "rweekly",
work_from_others = !blog &!my_code & !ropensci_onboarding & !ropensci_misc & !rweekly) %>%
tidyr::gather("organisation", "value", blog:work_from_others) %>%
dplyr::filter(value)
Again we filter event types, even removing watch/starring events this time.
orgs %>%
dplyr::filter(type %in% c("push", "issue comment",
"issues",
"create", "pull request"))%>%
ggplot() +
geom_bar(aes(organisation, fill = type)) +
theme_ipsum(base_size = 20,
axis_title_size = 16) +
theme(strip.text.y = element_text(angle = 0),
axis.text.x = element_text(angle = 90, hjust = 1)) +
ggtitle("My Github contributions in the two last years",
subtitle = "Data queried from Github archive on Google BigQuery") +
viridis::scale_fill_viridis(discrete = TRUE)
orgs %>%
dplyr::filter(type %in% c("push", "issue comment",
"issues",
"create", "pull request"))%>%
ggplot() +
geom_bar(aes(organisation, fill = type),
position = "fill") +
theme_ipsum(base_size = 20,
axis_title_size = 16) +
theme(strip.text.y = element_text(angle = 0),
axis.text.x = element_text(angle = 90, hjust = 1)) +
ggtitle("My Github contributions in the two last years",
subtitle = "Data queried from Github archive on Google BigQuery") +
viridis::scale_fill_viridis(discrete = TRUE)
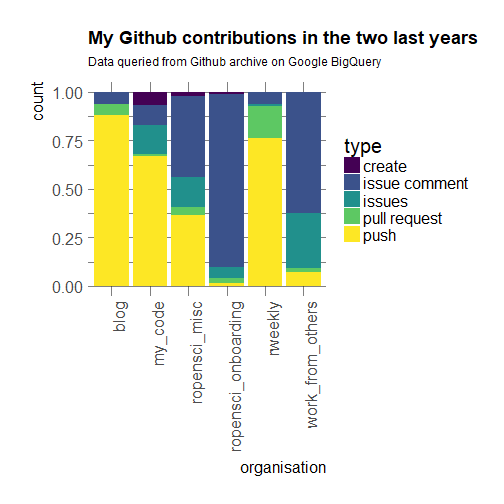
It looks as if blogging were a very small part of my work in my own repos but I think it’s due to the fact that I mostly push all material related to one blog post at once. Interestingly I seem to only create repositories under my own brand, which I think is true in general, although I did end up transferring a few packages to rOpenSci. Then, clearly in rOpenSci onboarding, I seem to have done a lot of issue commenting/labelling, etc. This is no surprise. I have also done that for miscellaneous repositories that do not belong to me: I have contributed a bit of code but have talked a lot. As mentioned earlier, my R Weekly contributions are mostly my committing one new entry each time I read something good.
What about you, dear readers?
I think I have only scraped the surface of how one could use Github data to profile themselves (or others, of course). Not to mention all the things one could do with Github archive… See this list for inspiration; and do not hesitate to add suggestions or links to your work in the comments! Where have you been?
Last but not least, if you’d like to contribute more to R, for instance on Github, you should check out these slides by Charlotte Wickham, they’re full of great tips!